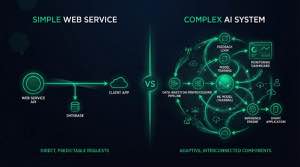
The most common mistake in AI projects? Treating AI like a web service — a stateless endpoint you call and forget. This mental model works for CRUD APIs. It fails catastrophically for AI systems.
Applied AI requires a fundamentally different approach: treating AI as a living system with its own lifecycle, dependencies, and failure modes. The teams that understand this ship systems that work. The teams that don’t ship demos that degrade.
If you want the broad operational answer to why machine learning models degrade in production, start there. This article explains why the web-service mental model causes those failures in the first place.
Key Takeaways
- AI systems are stateful, non-deterministic, and silently degrading. Every assumption that works for a web service breaks for an AI system.
- Silent failure is worse than loud failure. A model returning confident wrong predictions with 200 OK is harder to detect than a 500 error — and causes more damage.
- Deployment is the beginning, not the end. The maintenance phase — monitoring, retraining, data pipeline upkeep — has no defined end date. Budget for it from day one.
- Data is infrastructure, not input. Version it, monitor it, and build explicit contracts with upstream providers.
- Retraining is an operational requirement, not an edge case. A model trained on 2022 data is making 2026 decisions on a changing world.
I. The web service mental model
Traditional web services are operationally simple:
- Stateless — each request is independent
- Deterministic — same input produces same output
- Stable — behavior only changes on deploy
- Fails loud — 500 errors, timeouts, stack traces
You build it, deploy it, monitor response codes and response time, and move on. SLA is uptime and latency. The mental model is clean and it works.
The problem is applying it to systems that violate all four properties by design.
II. Why AI breaks every assumption
AI systems violate all four assumptions above — and the violations are not edge cases. They are fundamental properties of how machine learning works.
The most dangerous violation is silent failure. A web service tells you when it breaks. An AI system doesn’t.
III. The silent decay in action
A model trained at 95% accuracy will degrade silently over weeks and months. Without layered monitoring, you discover the problem only when a business metric craters — after the damage is done.
The interactive timeline below shows the difference between “no monitoring” and “layered monitoring” across a 180-day production window. Drag the slider to see how the same underlying drift plays out differently depending on observability.
The pattern is consistent across every domain: CV, fraud, trading, recommendations. The decay is silent, the infrastructure stays green, and the only question is how long it takes you to notice.
At Steve Trading Bot, market regime shifts can invalidate a model’s signals without producing any system error. The model continues generating predictions with the same confidence — but the underlying market structure has changed. Without explicit regime detection and monitoring, you don’t know until you’ve taken losses.
At AgrigateVision, a camera firmware update changed image preprocessing parameters without touching a line of our code. The model’s input distribution shifted. No exception was thrown. The pipeline failure was only caught because we monitored input distributions.
For the full taxonomy of production failure modes, see why ML models degrade in production.
IV. The hidden costs
When teams apply the web-service mental model to AI, they pay these costs downstream — usually after it’s too late to avoid them.
Technical debt compounds faster. Hardcoded preprocessing in the serving layer diverges from training code. Schema changes in upstream data sources aren’t treated as breaking changes. Every “quick fix” in serving creates another potential training-serving skew source.
Retraining becomes expensive and risky. Without data versioning, retraining requires reconstructing the exact training dataset — which may no longer be possible if sources changed. Teams that don’t version training data eventually can’t reproduce past model behavior.
Monitoring overhead grows without structure. Adding monitoring reactively — after each incident — produces a pile of ad-hoc alerts with no coherent model health picture. Proactive monitoring architecture costs 1× to build. Reactive, incident-driven monitoring costs 5–10× over time.
Rollback is harder than a web service. Rolling back a web service means deploying the previous Docker image. Rolling back an ML model means reverting weights and ensuring the feature pipeline produces the same values the old model expects. Without versioned feature stores, this is painful or impossible.
V. The system mindset shift
To build AI that works in production, shift from “endpoint” to “system” thinking.
Treat data as infrastructure
Data is not input — it’s infrastructure:
- Version your datasets like code (DVC, Delta Lake, or S3 + manifest files)
- Monitor data quality with automated schema and distribution tests at ingestion
- Track lineage from source to prediction
- Build explicit contracts with upstream data providers — they are dependencies, and dependencies change
Example: At AgrigateVision, camera hardware is a data dependency. A firmware contract and automated input distribution monitoring would have caught the shift before it caused a pipeline failure.
Design for observability from day one
Four layers of monitoring — not one:
| Layer | What to monitor |
|---|---|
| Infrastructure | CPU, memory, latency, error rates |
| Pipeline health | Data freshness, schema compliance, null rates |
| Model health | Input PSI per feature, prediction distribution, confidence drift |
| Business outcomes | Conversions, fraud caught, decisions made, revenue impact |
Infrastructure-only monitoring is table stakes. It catches servers going down — not models going wrong.
Plan for the full lifecycle
An AI system is never “done”:
| Phase | Activities |
|---|---|
| Development | Training, evaluation, iteration |
| Deployment | Serving, scaling, integration |
| Monitoring | Drift detection, alerting, segment analysis |
| Maintenance | Retraining, updating, deprecating |
The maintenance phase has no defined end date. This is the most important difference from a web service — budgeting, staffing, and architecture must account for it from day one.
Build feedback loops
Production data is your best training signal:
- Log model inputs and outputs at inference time
- Collect outcome labels when possible
- Build annotation pipelines for edge cases
- Use production data to drive retraining cadence
VI. Domain-specific implications
Computer Vision
CV systems need input health monitoring (image quality, exposure, noise levels), drift detection for visual changes (seasonal, environmental, hardware-driven), and edge device considerations where connectivity and compute constraints change the architecture. Our approach: Computer Vision in Applied AI.
Trading Systems
Trading bots need real-time risk controls that operate independently of ML predictions, reproducible backtests for auditability, explicit market regime detection, and execution quality monitoring (slippage, fill rates, latency). A model operating in a regime it wasn’t trained on is worse than no model. See Trading Systems & Platforms and the deep dive on regime-aware grid trading.
LLM and RAG Applications
LLM systems need retrieval quality monitoring (embedding drift, chunk relevance), cost tracking per request (token usage compounds non-linearly), safety guardrails, and user feedback loops. The unique challenge: a wrong SQL query throws an exception. A wrong LLM answer looks confident and coherent. See RAG Architectures in Production.
VII. Diagnostic: am I thinking in systems?
Frequently asked questions
Why do AI projects fail after deployment? The most common reasons: no monitoring for data drift or model degradation (failures go undetected for weeks), training-serving skew (model sees different features in production than in training), no ownership clarity (nobody knows who to page when accuracy drops), and treating retraining as a one-time event. The underlying cause is applying web-service assumptions to a system that violates all of them.
What is the difference between an AI system and a web service? A web service is stateless, deterministic, and stable — it only changes on deploy. An AI system is stateful (depends on training data and feature stores), non-deterministic (same input can produce different outputs), and degrades silently over time as input distributions shift. These differences require a fundamentally different operational approach.
What is production ML monitoring? Production ML monitoring tracks model health across four layers: input distributions (are inputs similar to training?), prediction distributions (is the model behaving normally?), outcome tracking (are predictions correct?), and business outcomes (are the metrics that matter improving?). Infrastructure monitoring (CPU, latency) is necessary but not sufficient.
What is training-serving skew in machine learning? Training-serving skew is when the model sees different data at inference time than it did during training — due to different preprocessing code, different feature versions, or different null handling. It’s one of the most common causes of production ML failures and is invisible until you compare training feature distributions to live feature distributions.
How is AI delivery different from traditional software delivery? Traditional software delivery has a defined end state — you ship a version, it either works or it doesn’t. AI delivery is continuous: models degrade, data drifts, and retraining is an ongoing operational requirement. Success criteria include not just initial accuracy but sustained accuracy over time.