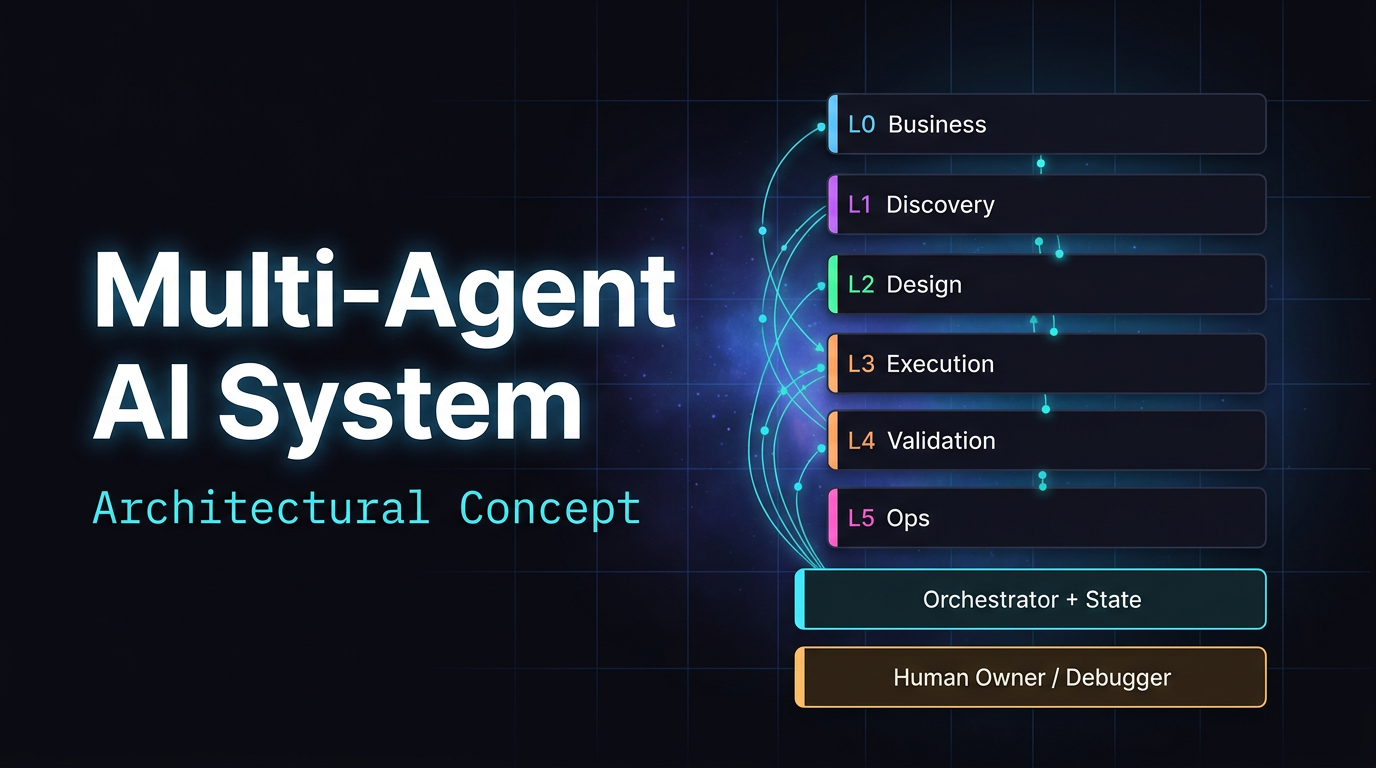
A multi-agent system is not magic and not a silver bullet. It is a way to structure complexity: decompose a large task into specialized roles, introduce explicit verification gates, and create conditions where an error from one agent is more likely to be caught before it propagates to the end of the pipeline.
What follows is an honest architectural concept — not a promise of a ready-made production solution.
Key takeaways
- This is a mental framework, not a blueprint. The described scheme requires adaptation to a specific domain, team, and acceptable risk level.
- More agents ≠ better. Each new role adds coordination overhead, error surface, and debugging complexity.
- Confidence score is a heuristic, not a reliability metric. You cannot build routing solely on a model’s self-reported guess.
- RAG ≠ knowledge. Retrieval gives access to documents — the model can still misinterpret them.
- The human is not just an approval gate. They are the key element of control, debugging, and the source of truth in non-standard failures.
- The system is designed to be manageable, but remains partially unpredictable. Limits, gates, and checkpoints are mandatory elements, not optional ones.
- I. The Managed Development Loop
- II. Evolution of a Single Agent
- III. Why Multi-Agent
- IV. Interactive Roles Map
- V. What Makes the System Manageable
- VI. Orchestrator + Agent: Reference Pattern
- VII. Failure Modes and Trade-offs
- VIII. Closing Thoughts
I. The Managed Development Loop
Before decomposing the process into agents, we need to understand the loop we are trying to partially automate. Below is not “the truth about software development,” but a convenient reference model: from cold start to a closed cycle with metrics and return to analysis.
Ideal model — linear route with explicit transitions. Real system — graph with bypass routes, urgent escalations, and coordination overhead.
CustDev here is a cold start, but not a mandatory ritual before every iteration. The useful Monitor → BA cycle returns operational signals to requirements formulation and hypothesis generation.
The system is designed to be manageable, but by its nature remains complex and partially unpredictable. The “Ideal Model” button shows the desired route. “Real System” is a reminder: in practice, a graph of feedback loops, bypass routes, urgent escalations, and coordination overhead emerges.
II. Evolution of a Single Agent
Before scaling the system, it is useful to understand what we actually mean by a single working agent. Below are not steps from “dumb to smart,” but three levels of architectural maturity.
Level 0: Template generator
A basic agent is an LLM with a rigid prompt template. It does not “understand the domain” — it generates a response in the required form based on general patterns from training data.
SYSTEM: You are a Spec Writer. Receive the task and return JSON:
{ "requirements": [...], "edge_cases": [...] }
USER: "Build a REST API for task management"
# Limitation: the model does not see project context,
# does not rely on local decisions, and easily
# generates an averaged but not necessarily relevant answer.Level 1: + RAG — access to documents, not “knowledge”
RAG gives the agent access to retrieved documents. This is useful, but the effect should not be overestimated: retrieval does not turn an LLM into a reliable expert. The model can still misinterpret the retrieved context, pick the wrong document, or amplify retrieval bias.
1. Receive the task
2. → Search Vector DB: "REST API best practices 2026"
3. Get context: OpenAPI 3.1 spec, FastAPI patterns, ADR
4. LLM generates response based on task + context
5. Return self-reported confidence: 85
# Important: retrieved docs ≠ ground truth.
# Confidence here is a heuristic, not a reliability metric
# and certainly not a probability that the answer is "correct."Confidence score cannot be read as a probability of success. It is typically the model’s self-reported guess about the quality of its own response. It can be used as an additional routing signal, but not as the sole decision criterion.
Level 2: + checks, tool use, and execution limits
The next step is not “human-like reasoning,” but adding checks and external tools. MCP provides access to APIs, databases, and the file system — but with it come new problem classes: latency, flaky tool calls, side effects, retry logic, and the need for sandboxing.
BEFORE_EXECUTE:
Check input for completeness → if unclear, request clarification
Search RAG for relevant context
List risks, constraints, and alternatives
EXECUTE:
Call MCP tools: read_file, query_db, search_docs
Handle latency / tool errors / retry / sandbox policy
Generate response based on RAG + tools
AFTER_EXECUTE:
Return self-reported confidence: 0-100
If signal is weak or tool call is unstable → needs_review
List risks, assumptions, and potential side effectsA practical agent is not a “digital employee,” but an LLM loop with retrieval, tools, execution limits, and explicit escalation to a human where the cost of error is high.
III. Why Multi-Agent
A multi-agent system is a way to decompose complex work into several specialized loops. One generates the specification, another proposes architectural options, a third implements artifacts, a fourth validates, a fifth verifies independently.
Important: more agents does not automatically mean a better result. Increasing the number of roles expands capabilities, but simultaneously sharply increases coordination cost, error surface, and debugging complexity.
Benefits of the multi-agent approach:
- Scalability — a role can be added, but coordination overhead grows with it
- Division of labor — specialization is useful when roles and contracts genuinely differ
- Flexibility — roles can be changed, but each restructuring costs time and reconfiguration
- Independent verification — separate QA and audit loops reduce risk, but do not eliminate it
Non-linearity matters: a system of 20 agents is not simply “20× harder” than one — it is fundamentally different in the nature of its coordination problems.
IV. Interactive Roles Map
Below is the ideal roles map: who generates what, which documents are used, where manual control is required. In a real system, all these lines are typically noisier, more expensive, and less symmetric than the diagram suggests.
👆 Click any agent, orchestrator, or Human PM to see details
Three key observations about the map:
-
The orchestrator is an algorithm, not an agent. It routes tasks, stores state, and enforces limits. Making substantive decisions is not its function.
-
The human is not just ⏸. In non-standard situations, incidents, and structural failures, the human is the source of truth and the system debugger.
-
A knowledge graph is useful but does not eliminate interpretation errors. Neo4j or NetworkX links decisions to context, but does not guarantee that an agent will correctly interpret those links.
V. What Makes the System Manageable
The list is not exhaustive, but covers the most frequent causes of failure in real multi-agent systems.
- Testability first. Not all work should go to code before expected behavior is formalized.
- Explicit architectural boundaries. Roles, inputs, and outputs are described before the cascade is launched.
- Independent audit. Reduces cascading error risk, but provides no guarantee of error-free execution.
- Discovery before execution. Otherwise the system optimizes an incorrectly framed problem.
- WIP limits and gates. Without them, a multi-agent flow is a noisy artifact queue.
- Strict contracts. Input/output format and acceptance criteria matter more than well-crafted prompts.
- Logging and traceability. Without logs, such a system is nearly impossible to debug.
- Iteration caps. Basic protection against “fix it just a little more” loops.
- Role-specific retrieval. RAG is useful as a document source, not as a substitute for verification.
- Orchestrator state store. Checkpoints, decision rationale, and escalation routes are required.
- Ops on runbooks. A DevOps agent can automate part of reactions, but does not “hold prod alone.”
- Knowledge curation. A live RAG is only useful when ingestion and document quality are controlled.
- Checks over anthropomorphism. Verification and validation are needed — not faith that the agent “will figure it out.”
- Monitor → BA. Operational signals must return to hypothesis and requirements formulation.
VI. Orchestrator + Agent: Reference Pattern
Below is an idealized reference pattern — convenient to discuss and adapt. This is not a claim that the same scheme works equally well for any role, domain, and risk level.
The orchestrator has explicit routing rules, the agent receives quality context, tools respond stably, and checks stop bad artifacts in time.
Context may be incomplete, a tool call may fail or return a stale response, confidence may mislead, and some errors surface only after manual review.
Orchestrator (Python)
class Orchestrator:
def __init__(self):
self.db = PostgresStateDB() # persistent memory
self.queue = RedisQueue() # task queue
self.agents = {} # agent registry
def register(self, role, agent):
self.agents[role] = agent
def run(self, task):
self.db.checkpoint(task) # save state
stage = self.db.current_stage(task)
agent = self.agents[stage]
result = agent.execute(task, self.db.context(task))
if result.needs_review or result.tool_errors:
return self.escalate(task, result)
if not self.validate_contract(stage, result):
return self.route_rework(task, result)
self.db.save_artifact(task, stage, result)
self.db.advance(task) # next stage
self.queue.enqueue(task) # continueAgent with RAG + MCP
class Agent:
def __init__(self, role, system_prompt):
self.llm = Claude(model="claude-sonnet-4-20250514")
self.rag = VectorDB(collection=role) # role-specific retrieval
self.mcp = MCPClient(tools=[ # external tools
"read_file", "query_db", "search_docs"
])
self.prompt = system_prompt
def execute(self, task, context):
# 1. Retrieve documents — do not treat them as ground truth
rag_docs = self.rag.search(task.description, top_k=5)
# 2. Assemble context and flag what is MISSING
full_context = {
"task": task,
"prev_artifacts": context, # from previous agents
"rag_knowledge": rag_docs,
"missing_info": detect_gaps(task, context)
}
# 3. Call LLM with MCP tools, retry policy, and sandbox
response = self.llm.call(
system=self.prompt,
messages=[full_context],
tools=self.mcp.tools
)
# 4. Response + heuristic quality signals
return AgentResult(
output=response.content,
confidence=response.confidence, # self-reported guess, not probability
risks=response.risks,
tool_errors=response.tool_errors,
needs_review=response.confidence < 70 or bool(response.tool_errors)
)Increasing agent count from N to N+1 does not linearly add one role — it adds N new potential interactions. Complexity grows non-linearly, which is one of the key arguments for minimizing the number of agents at the start.
VII. Failure Modes and Trade-offs
Multi-agent systems are susceptible to specific failure classes. Below are known patterns with an interactive readiness checklist.
Known failure modes of multi-agent systems
Agent A returns the task to Agent B, which sends it back to A. Without WIP limits and iteration caps the system enters an infinite loop. Detectable only through explicit route logging.
Spec Agent formulates one thing, Backend Agent interprets it differently, QA checks a third version. By audit time the gap is buried across multiple artifacts and the source of divergence is hard to trace.
QA Agent checks only against written test cases. If test cases don't cover an edge case or incorrectly formalize a requirement — the defect passes through. A separate Auditor reduces this risk but doesn't eliminate it.
A wrong fact at Research or Hypothesis propagates through Spec → Architect → Backend. Each agent "trusts" the previous agent's artifact. Without an independent Auditor the error reaches deploy.
The orchestrator passes only the last artifact, not the full decision chain. Backend Agent doesn't know why a particular architecture was chosen. Fix: explicit State Store with ADR history.
An MCP tool returns a timeout, stale response, or crashes with 5xx. Without a retry policy and sandbox the agent treats this as a valid result and continues on bad data.
The orchestrator routes the task forward because confidence = 89. But that is a self-reported model guess, not a correctness probability. Systems that rely solely on confidence miss structural errors.
Applicability boundaries
- Artifact generation: code, specs, tests
- Internal tools and automation
- Accelerating development with human oversight
- Domains with high repeatability and formalizable rules
- Prototyping and exploratory projects
- Safety-critical systems (medical, aviation, critical infrastructure)
- High-reliability infra with strict SLAs
- Domains with regulatory requirements for full traceability
- Tasks where cost of error outweighs cost of manual oversight
- Systems without resources to support coordination overhead
Deployment readiness checklist
Check items — the system will highlight what needs attention.
Chaos, entropy, and control
A multi-agent system is a non-linear dynamic system with feedback loops. A small error at the CustDev or Hypothesis level can lead to a spec mismatch that is only discovered after deploy. This is not a reason to abandon the multi-agent approach — it is a reason to design with explicit limits, gates, checkpoints, independent verification, and a human who can stop the cascade.
Key measures against chaos:
- Checkpoints — explicit state at each pipeline point
- WIP limits — constraint on parallel tasks
- Independent Auditor — verification loop separate from QA
- Iteration caps — hard limit on rework attempts
- Human escalation path — there is always a route to a human
VIII. Closing Thoughts
A multi-agent system is not “hire 20 bots and go home.” It is an architectural decision about how to structure complexity: through roles, contracts, checks, and human control points.
This approach creates conditions for more manageable development — provided that you:
- have explicitly defined the applicability boundaries
- have built in independent verification
- are not relying on confidence as the sole signal
- have kept the human in the role of debugger, not just approver
Complexity does not disappear when agents are added. It is redistributed — and becomes visible through logs, artifacts, and escalations. That is the architectural goal: not to remove complexity, but to make it manageable.
FAQ
What is a multi-agent system in software development? It is a way to decompose a complex task into specialized roles (research, specification, implementation, validation, monitoring), each operating as a separate LLM loop with explicit inputs, outputs, and contracts. Agents are coordinated through an orchestrator with a persistent State Store.
How does a confidence score differ from a real probability of a correct answer? A confidence score is the model’s self-reported guess about the quality of its own response. It is not calibrated and is not a true probability of correctness. It can be used as an additional routing signal (e.g., “send for review if confidence < 70”), but critical decisions cannot be built solely on it.
What are the limitations of RAG in multi-agent systems? RAG gives an agent access to retrieved documents, but does not make it an expert. Key risks: retrieval bias (wrong documents in top-k), false interpretation of correctly retrieved documents, knowledge base staleness without curation. Retrieved docs ≠ ground truth.
When is a multi-agent system not suitable? For safety-critical systems (medical, aviation, critical infrastructure), systems with strict SLAs, domains with regulatory requirements for full traceability, and cases where manual oversight cost is disproportionately lower than agent coordination overhead.
What is spec drift and how do you prevent it? Spec drift is the gradual divergence between what the Spec Agent formulated and what the Backend Agent implements. Prevented by explicit contracts (input/output format), a persistent State Store with artifact history, and an independent Auditor that compares the final artifact against the original specification.
What is the human’s role in a multi-agent system? The human is a key system element: source of truth in non-standard failures, debugger in cascading errors, decision-maker when error cost is high. Not just an “approval gate” — an active control participant without whom the system loses the ability to correct systemic errors.
See Also
- Applied AI is not a web service — why the “service as API” mental model breaks AI projects
- RAG Architecture Patterns — retrieval-augmented generation patterns in production
- MCP, OpenAPI, and the Missing Runtime Layer — how agent hosts discover and invoke external tools at runtime
- Why ML Models Degrade in Production — 5 failure modes applicable to agentic systems too